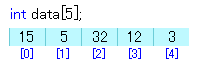
以下のような変数にデータが入っているとします。
なお、配列が分からないと言う人は、まずC言語の勉強からしてください。
ここでは普段、自分が使うプログラム手法について説明しています。
マスターすれば音ゲーに限らず独自のプログラムにも応用することができます。
なお、このアルゴリズムはゲームサンプルにも使用しているものなので必ず覚えましょう。
このページは以下の内容について説明しています。
プログラミングの中で、初歩中の初歩、並び替えのアルゴリズムです。
ここで紹介するものは、スピードは遅いですが一番理解しやすいやり方なので、
並び替えの原理を知らない人は、まずこれを完璧に覚えましょう。
というか、試験とかにもよく出るみたいです。
なお、数字の小さい方から大きい方へデータを並び替えることを「昇順(しょうじゅん)」と言います。
逆に、大きい方から小さい方へ並べることを「降順(こうじゅん)」と言います。
それではまずサンプルデータを用意します。
以下のような変数にデータが入っているとします。
なお、配列が分からないと言う人は、まずC言語の勉強からしてください。
ではアルゴリズムを考えてみましょう。
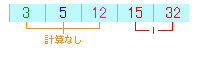
まず始めに考えることは1番目の配列に、一番小さい数を持ってくるということです。
ということは、その数と他の配列の数を比較して、
小さい場合にそのデータと交換すればいいということになります。
以下の図を見てください。
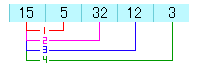
1回目の比較では15と5では5の方が小さいので、これを交換します。
すると下のような配列になります。
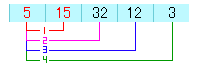
これで5が一番最初に来たので、2つ目の比較は5と32の比較になります。
5と32では32の方が大きいので配列はこのままになります。
3つ目の比較では、5と12を比較します。
ここも12の方が大きいので、配列はこのままになります。
最後の比較では、5と3を比較します。
これは3の方が小さいので、交換をすることになります。
そして、これらの比較が終わったら以下のようになります。
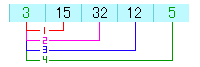
これで、 一番小さい3と言う数字が始めの配列になっていることになります。
この比較を配列の数だけ行いますが、これをもっと詳しく説明します。
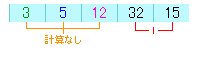
次にやることは、2つ目の配列とその他を比較することです。
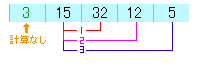
1回目の比較は15と32となり変動なし。
2回目の比較は15と12となり、12の方が小さいのでこれは入れ替えます。
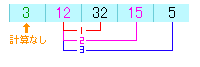
3回目の比較は12と5となり、5の方が小さいので入れ替えます。
これで2つ目の配列には、2番目に小さい値になっていることになります。
ちなみに、1つめの配列とは比較する必要はありません。
分かると思いますが、その比較は以前に行っているからです。
さて、今度は同じように次の配列の数と他を比較します。
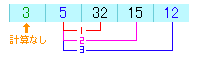
1回目の比較では32と15で、15の方が小さいので入れ替えます。
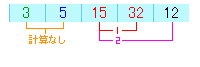
2回目の比較では15と12で、12の方が小さいので入れ替えます。
これで3つ目の変数は、3番目に小さい値になっていることになります。
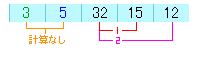
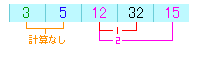
そして、最後に4つ目の配列と最後の配列を比較して終了となります。
32と15を比較すると、15の方が小さいので交換します。
ちなみに5個目の配列と他と比較する必要はありません。
5個目の配列の他と言うのは、かならずそれより小さい数になっているからです。
さて、よく見るとデータがきちんと並べられています。
これで並び替えが終了となります。
では、これをプログラムにしたらどうなるか書いてみましょう。
#define ARRAY 5 // 配列の数を定義 void SortTest( void ) { int i,j; int data[ARRAY] = { 15,5,32,12,3 }; for( i=0;i<ARRAY-1;i++ ) { for( j=i+1;j<ARRAY;j++ ) { if( data[i]>data[j] ) { int dmy = data[i]; data[i] = data[j]; data[j] = dmy; } } } // 表示してみる for( i=0;i<ARRAY;i++ ) printf( "%d¥n",data[i] ); } |
1つ目のfor文は現在の比較対象の配列番号で、上の説明で言う左側の数を指します。
比較数を-1しているのは、説明したとおり、最後の配列の比較がいらないためです。
2つ目のfor文はそれより上の比較用の配列番号となり、上の説明では右側の数を指します。
このため、jの初期化にはi+1とし、iの次の配列から比較するようになっています。
入れ替えは、始めにダミーの変数にバックアップを取っておき、それをあとで入れ替え先に入れなおします。
ちなみに比較部分のif文でdata[i] > [data[j]としていますが、この比較を逆"<"にすることで降順に並べることが可能です。
sizeof()というのは、構造体のバイト数を自動で計算する関数です。
自分で計算してもいいですが、構造体の中身を増やしたときなど、sizeofを使うことで楽になり計算ミスもありません。
たとえば以下のような構造体を作ったとします。
typedef struct _MYDATA { int id; char data[256]; } MYDATA; |
この構造体のサイズは sizeof(MYDATA) で求めることが出来ます。
この場合のバイト数を計算してみると、intは4バイト、data[256]は256バイトなので、加算すると260バイトということになります。
sizeof()の引数には構造体の他に、intやcharなどの定義も入れられます。
知ってのとおり、Windowsではintは4バイトで、charは1バイトになります。
ただし、1つ重要なこととして通常はどのようなコンパイラにはアライメントという機能があります。
これは、CPUの高速化のためメモリの区切りを自動で8バイト区切りなどに変更してしまうもので、
たとえばchar data[3]だけの構造体のサイズは実際は8バイトになってしまい、残りの5byteは何も使われない領域となります。
これを避けるにはコンパイラオプションでアライメントを1バイトに設定するか、
必ず8の倍数になるようにわざとchar dmy[5]という感じでダミーを追加する必要があります。
特にVisualC++以外のコンパイラはアライメント数が異なる可能性があるので、データを共有するようなアプリを作成する場合は、
このあたりを気をつけて実装する必要があります。
パソコンにはメモリと言うプログラムを実行するときにそのプログラム自体を置いたり、
そのプログラムで使用している変数などのデータを保存しているところがあります。
プログラムを組む場合、初心者はよく配列を多様して作ることが多いと思いますが、
普通にchar str[1000];と打った状態でこのプログラムを起動すると、
起動時に1000バイトのデータ領域をメモリから取ってしまい、
プログラムが終了するまで保持されます。
これがもし、str[10][1000];などと複数定義した場合、それにつられてメモリを消費します。
ちなみにこのようにプログラムで固定で定義することを静的確保といいます。
このデータ量ではまだ問題になりませんが、モノによっては1MBなどを確保したりしないといけない場合があります。
プログラムを組んでいる状態で、1Mのメモリをグローバル変数で確保するなんてことは通常はしてはいけません。
大きすぎるとコンパイル自体通らなくなります。
そして、もしプログラムの起動時にメモリが確保できなければ、
以下の用にプログラム自体をロードする瞬間にOSがエラーを出して強制終了されます。
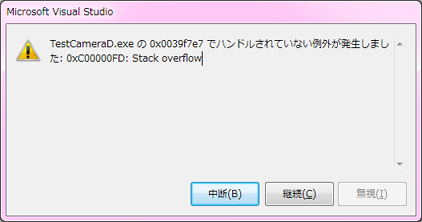
これだと、実行した本人はなんで起動しないのか分かりません。
また、逆に1MBでも足りない場合はどうするでしょうか。
始めから最大の容量を変数で確保するという方法もありますが、上での説明の出来事がさらに起こる可能性が出るということになります。
これを避けるには、プログラム内で必要なときに必要な容量のメモリを確保するようにします。
このことを動的確保と言い、メモリが確保出来なければエラーを返すので、その項をユーザーに伝えることも出来ます。
この動的確保では、32bitのOSでは理論上2GBまで確保できるようになっています。
ただし、メモリがきちんと乗っかっている場合の話ですが。
それではメモリを確保するための関数を説明します。
| void *malloc( size_t size ); | メモリを確保します。 Windowsでは引数のsizeはバイト単位となります。 確保されれば、戻り値にはそのメモリのポインタが返ります。 もし確保出来なければNULLが返ります。 void型のポインタなので、変数に入れる場合キャストが必要です。 例) char *msg = (char *)malloc( 100 ); |
| void *realloc( void *memblock, size_t size ); | メモリの再確保をします。 以前のメモリ状態を保持したまま、そのメモリのサイズを変更できます。 memblockには以前のメモリポインタを代入しますが、 これがNULLの場合、mallocと同じ動作を行います。 例) char *msg = NULL; msg = (char *)realloc( msg,100 ); |
| void free( void *memblock ); | メモリを開放します。 引数には、mallocなどで確保したときに返されたポインタを指定します。 |
| new | mallocと同等の機能ですが、C++のみ使用できます。 詳しく書くと長くなるのでやめますが、構造体の他に、 変数やクラスの実態を作ることも出来ます。 例) char *msg = new char[100]; |
| delete | newで確保したメモリ領域を開放します。C++のみ使用できます。 配列を確保した場合は、若干書き方が違います。 例) delete [] msg; |
malloc系の関数で確保されたメモリは基本的にdeleteで開放してはなりません。またその逆も同じです。
※厳密にはnewやdeleteは内部でmallocやfreeを使っているため、コンストラクタやデストラクタを使っていない場合は呼び出すことが出来ます
また、newで確保した領域を再確保するというものは用意されていません。
これはポインタの配列使うなどで自分で実装しなければなりません。
簡単な割に実は結構面倒だったりするのがnewとdeleteでの配列確保なので、
ここでは基本的にnewとdeleteはクラスの実体を作るときにしか使わないようにしています。
メモリを確保したら、必ずプログラムの終了前に開放する必要があります。
これを忘れるとメモリリーク(その領域が残ってしまい他のアプリからも使用できなくなる)が発生してしまいます。
1つのmallocに対して1つのfreeが必要なため、これらの関数は1対1で使用します。
ちなみに、メモリ確保という動作は、スピードがかなり速いため、毎回、確保・開放を繰り返しても問題ありません。
以下に自分が良く使う使用法を紹介します。
// 構造体MYDATAの定義 typedef struct _MYDATA { int id; char data[256]; } MYDATA; int iMyData = 0; // MYDATAの現在の数 MYDATA *pMyData = NULL; // MYDATAの実データ // MYDATAを追加する BOOL AddData( MYDATA *data ) { iMyData++; pMyData = (MYDATA*)realloc( pMyData,sizeof(MYDATA)*iMyData ); memcpy( &pMyData[iMyData-1],data,sizeof(MYDATA) ); return TRUE; } // 指定の配列を削除 BOOL DelData( int array ) { if( array<0 || array>iMyData-1 ) return FALSE; if( iMyData>1 ) memmove( &pMyData[array],&pMyData[array+1],sizeof(MYDATA)*(iMyData-array-1) ); iMyData--; return TRUE; } |
このサンプルは構造体で定義されたMYDATAリストを、いくつも追加したり削除したりできる関数です
ここではAddData内でreallocを使ってメモリを再確保させています。
一番始めはデータが何もない状態なので、pMyDataはNULLとなりmallocと同等の役割をします。
その後、2つ目以降のデータが追加される場合には、以前のデータを残したまま配列を追加するようになっています。
ちなみに、このサンプルではメモリ確保失敗のエラー処理はしてません。
この作り方は、メモリがあればある分だけデータを追加できるという利点があります。
配列のように数が決められていないので無限に確保することが出来ます。
削除では、まず指定の配列番号が存在するか確認します。
存在したらそのデータから1つあとのデータを、消したい配列の場所へ移動します。
これで指定の配列の中のデータは上書きで消去されることになります。
最後にデータ数を1引いて完了です。
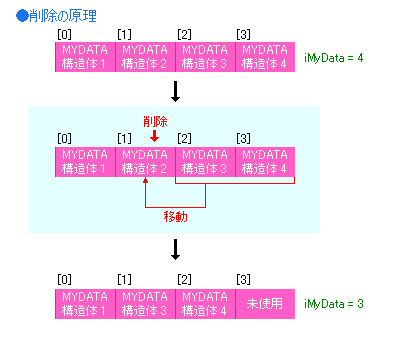
ここでは減らした分のメモリの再確保は行っていません。
きちんと行ってもいいですが、メモリもすでに確保されているわけなので、
スピード的にやってもただの無駄になります。
最後にプログラムの終了時に mMyDataがNULLでなければfree( mMyData ); とすることで、
完全にメモリを開放でき、メモリの有効活用ができます。
if( pMyData ) {
free( pMyData )
pMyData = NULL;
}
|
あるテキストの文章から、その内部を取り出して別の文字変数へ代入するというやり方です。
よく設定ファイルから設定データを取得して使用したりしますが、
この操作をするにはテキストデータと言うのを理解しておかなければなりません。
なお、ここでは日本語操作についてはあまり触れていませんが、
紹介する方法では、基本的に日本語だといけないというのはありません。
ただし日本語は全角なため、1文字あたり2バイトになります。
まず、文字列に関しての関数を紹介します。
これらは良く使うため、頭に記憶しておきましょう。
ちなみにこれらの関数はstring.hに定義されているため、始めにインクルードしておきます。
| size_t strlen( const char *string ); | |
| 文字列の長さを取得します。 文字列はNULLで終わっている必要があります。 なお、最後のNULLは数えません。 |
|
| char *strcpy( char *string1, const char *string2 ); | |
| 文字列をコピーします。 string2からstring1へNULLまでをコピーします。 なお、バッファサイズのチェックなどは無いため、コピー元はきちんとNULLで終わっているかは、 プログラマーがチェックしなければなりません。 また、コピー先のバッファサイズもチェックしないため、メモリリークしてしまわないように、 バッファのサイズをきちんと管理しなければなりません。 |
|
| char *strcat( char *string1, const char *string2 ); | |
| string1の文字列の最後にstring2を付加します。 当然バッファのチェックが無いため、サイズはきちんと管理しましょう。 |
|
| int strcmp( const char *string1, const char *string2 ); | |
| 文字列を比較します。 同じなら 0 が返りますが、違う場合には以下のとおりに値を返します。 負 string1 が string2 より小さい 正 string1 が string2 より大きい これを利用して、文字列の並び替えを行うことが出来ます。 |
|
| int strncmp( const char *string1,
const char *string2, size_t count
); int strnicmp( const char *string1, const char *string2, size_t count ); |
|
| 前者は大文字小文字の区別を行い、指定の数だけ比較をします。 後者は大文字小文字を区別せずに比較します。 戻り値はstrcmpと同一です。 これは部分的な文字を比較したいときに使用します。 |
|
| char *strstr( const char *string1, const char *string2 ); | |
| 部分文字列を見つけます。 文字列があった場合、その最初のポインタを返します。 なお、ポインタが返されるため、参照するには注意が必要です。 文字が見つからなければNULLが返ります。 |
|
これらの中でよく使うものはstrlenとstrcpy、そしてstrcmpです。
strcmpは改行も文字として数えられるため、1行ずつデータを比較するといったことを行う場合は、
この改行を消しておく必要があります。
では、実際に文字を切り出すにはどうしたらいいか説明します。
まず切り出す文字列の配列をchar *src とし、切り出し先を char **dst とします。
なお、srcやdstは配列へのポインタですが、中身はきちんとメモリ確保されているとします。
つまり、src[1000],dst[n][1000]; として確保されているとします。
そしてsrcには、
"#TITLE 明日のナージャ"
と入っているとします。これを切り出した場合、
dst[0] = "#TITLE";
dst[1] = "明日のナージャ";
と言う風になればいいとします。
さて、ここで考えるのはどこで区切りがあるかと言うことです。
この場合ではスペースが区切り文字として使われているため、
スペースで分割してあげればいいということですね。
この例では、スペースは1個しかないため容易に考えることが出来ますが、
文字を打つ人は見た目を重視するため、スペースがいくつか入ったり、
タブを使ったりする場合もあるので、これらも対応できるように作るのがコツです。
以下のプログラムが実際のソースとなります。
char dst[10][1000]; // 10個の分割まで対応 // 文字列の分割 void CutString( char *src ) { int i,p,q; int len = strlen( src ); // 文字の長さ i = 0; // dstの1次元の配列 p = 0; // srcのポインタ ZeroMemory( dst,sizeof(dst) ); // dst配列を初期化しておく // src文字列の終わりまでループ while( p<len ) { // 始めのスペースを飛ばす while( p<len ) { if( src[p]!=' ' && src[p]!=0x09 && src[p]!='¥n' ) break; p++; } if( src[p]=='¥n' ) // 改行なら終了 break; // dstへ切り抜き q = 0; // dstの2次元の配列 while( p<len ) { if( src[p]==' ' || src[p]==0x09 || src[p]=='¥n' ) break; dst[i][q] = src[p]; p++; q++; } dst[i][q] = NULL; // dstの文字列の最後にNULLを付加(始めにdstを初期化しているため本当は必要なし) i++; // dstの配列を1つ上げる p++; // スペースやタブを飛ばす } } |
ここでやっていることは、分割したデータをdstに順番に入れていきます。
この例では10個分まで確保されているため、この数だけの分割が可能ですが、
プログラム内部では数をチェックしていないため、これより多い分割だとメモリが破壊されます。
チェックをきちんとやるようにすればかなり完璧な関数になります。
なお、タブのキーコードは0x09で改行は'¥n'としてチェック出来ます。
ここでは1行だけをチェックするため改行もチェックに入れています。
また、最初にスペースを飛ばすようにしているため、" #TITLE 明日のナージャ "というような、
スペース交じりの文章でも、正しくdst[0] = "#TITLE" dst[1]="明日のナージャ"
と分割されます。
ちなみにiniファイルなど、'='で区切られている場合は、このチェック部分を=にすればよい事になります。
数字の文字列をintやfloatにしたい場合の関数があります。
これを利用すれば、数字に変換するのが簡単に出来ます。
| int atoi( const char *string ); double atof( const char *string ); |
|
| stringには変換したい文字列の入った変数を代入します。 なお、変換できない場合には0または0,0が返るため、エラー処理は出来ません。 なので、文字列はきちんと正しく用意します。 |
|
上で説明した文字列のカットを使って、パラメータを数値に変換して使用するということも出来ます。
ただし、文字列から数値に変換するという処理はいろいろと手順があってとても重いため、
リアルタイムで処理をするルーチンで使うのは出来るだけ避けたほうがいいでしょう。
(変換した数値を変数で持っておくなど)